
Ollama 是一套能讓使用者在本地端輕鬆執行大型語言模型的工具。你不需要設定繁雜的 CUDA、PyTorch 或環境依賴,只要一條指令即可載入並使用 LLM,例如 Llama 3、Qwen、Mistral、Phi 3、Gemma 等主流模型。
這篇文章將以清楚的 SEO 結構介紹 Ollama 的特色、安裝方式、使用方法、適合的模型選擇,以及實際應用場景。
Ollama 的核心概念
本地端推論最大保障隱私
Ollama支援本地推論,也就是說讓模型運算以及資料處理都是在設備端完成,也不需要讓設備聯網,可以讓隱私以及機敏資料外洩機率大幅降低。
不需要配置模型環境
對於有在玩AI模型的玩家來說,環境部屬絕對是一大痛點,要創建環境、依據顯示卡及驅動程式版本調整依賴項目,最終還不見得讓模型順利跑起來。
但Ollama 把模型管理、格式轉換、硬體偵測打包成一體化流程,免去了環境部屬流程,現在只要幾行簡單的指令即可開始使用這些大型語言模型。
對於 API 非常友善
Ollama 提供 HTTP API,可直接整合至自己的程式、服務、自動化腳本與後端系統;或者你想要將他部屬到網路上進行遠端使用,也都沒有問題。
支援跨平台
Ollama 包含 Windows、macOS、Linux,並支援 NVIDIA、AMD、Apple Silicon 等硬體。
Ollama 的主要功能
1. 模型管理與下載系統
Ollama 內建完善的模型管理機制,能自動下載、更新與儲存模型檔案。
使用者已經不再需要自行處理 GGUF 格式、量化版本,也不需要手動配置模型路徑,整個使用成本大幅降低。
核心功能包含:
- 自動下載模型
- 模型版本切換
- 量化格式管理
- 本地快取與儲存機制
這讓使用者能快速取得 Llama、Qwen、Mistral、Phi、Gemma 等主流開源模型。
2. 本地端推論引擎(Local Inference Engine)
Ollama 提供高效能的本地推論引擎,可在 CPU、GPU(NVIDIA / AMD / Apple Silicon)上運行。在不同硬體環境下,會自動選擇最佳推論策略。
主要推論能力:
- 支援 GGUF 模型格式
- 多種量化加速(Q2~Q6 等)
- 自動偵測硬體資源
- 並行對話與多模型運行
這讓本地端使用大型語言模型時變得快速又穩定。
3. 互動式 Chat 介面(CLI 對話環境)
Ollama 內建簡潔的 UI 介面可以直接與模型對話,不需要額外安裝 Web UI。
特點包含:
- 即問即答的互動對話
- 可存取記錄
- 支援多輪對話
- 支援多模型隨時切換
這使得 Ollama 一開始就被大家稱作能當「本地版 ChatGPT」的程式。
4. 本地 API 伺服器(Local HTTP API)
Ollama 會自動啟動一個本地 HTTP API,讓開發者可透過程式呼叫模型,不需要額外架設伺服器。
API 提供:
- Text generation
- Streaming 回應(即時輸出)
- Chat / embedding 支援
- 與任何語言/框架整合(JavaScript、Python、PHP、Go 等)
這也是 Ollama 能輕易串接工具、插件、Workflow 的原因。
5. 自訂模型建構系統(Modelfile)
除了使用官方模型之外,Ollama 還提供 Modelfile,讓使用者可以:
- 基於某個 base model 建立新模型
- 加入預設 system prompt
- 內建特定角色設定
- 加載自訂資料
- 控制推論參數(temperature 等)
Modelfile 的概念類似 Dockerfile,是「模型定義檔」,可以產生你的專屬 AI 模型。
6. 模型打包與分發機制
Ollama 支援將自訂模型打包並分享給其他使用者,不需要傳送大量設定文件。
你可以使用 Ollama:
- 匯出模型
- 發布模型
- 建立可重現環境
這提升團隊協作效率,適合企業內部使用。
這可以提升整個團隊協作效率,非常適合企業內部使用或者遠端辦公室使用。
7. 跨平台支援與一致體驗
Ollama 提供 Windows、macOS、Linux 原生版本,且指令、模型格式、API 完全一致。
這意味著:
- 你可以在 Mac 上開發、在 Linux server 部署
- Windows 環境也能本地跑 LLM
- 文件與教學不會因平台而分裂
提供最接近「一次學會、到處使用」的體驗。
8. 高度整合的擴充生態圈
由於 Ollama API 架構簡單,大量生態系快速成長,包括:
- VSCode 插件
- Web UI(OpenWebUI、Chatbox 等)
- 自動化工具(LangChain、LlamaIndex)
- 輕量伺服器框架(Node.js、Python)
- RAG 架構整合
- Home Assistant / 其他 IoT 工具
Ollama 本身就是一個「本地 AI 平台」。
Ollama 可以用來做什麼?
建立本地 ChatGPT 替代方案
你可以像使用雲端模型一樣對話、翻譯、生成內容,但所有資料只存在本地。
開發 AI 工具與應用
包含:
- 桌面助理
- 自動化腳本
- 開發者工具
- VSCode 自動補全
- 後端 API
- Line bot / Discord bot
建立企業私有知識庫(RAG)
Ollama 可與向量資料庫搭配,例如 Chroma、Milvus、LlamaIndex、LangChain,用來構建完全私有的知识問答系統。
實驗不同模型與量化格式
方便比較:
- 7B vs 13B
- Q4_K_M vs Q6
- Llama 3 vs Qwen 2 vs Mistral
如何安裝 Ollama
Windows 及 macOS 安裝
可以直接前往 官網下載 安裝程式,安裝後開啟 Terminal 即可使用。
後面我們將使用Win版本進行介紹。
1. 前往 Ollama 官方網站下載對應作業系統的版本。
2.下載完畢後,點開所下載的檔案;當視窗開起後點選 Install,Ollama會自行進去安裝程序。
3.當 Ollama 自行安裝完畢之後,他會直接進入 UI 介面。
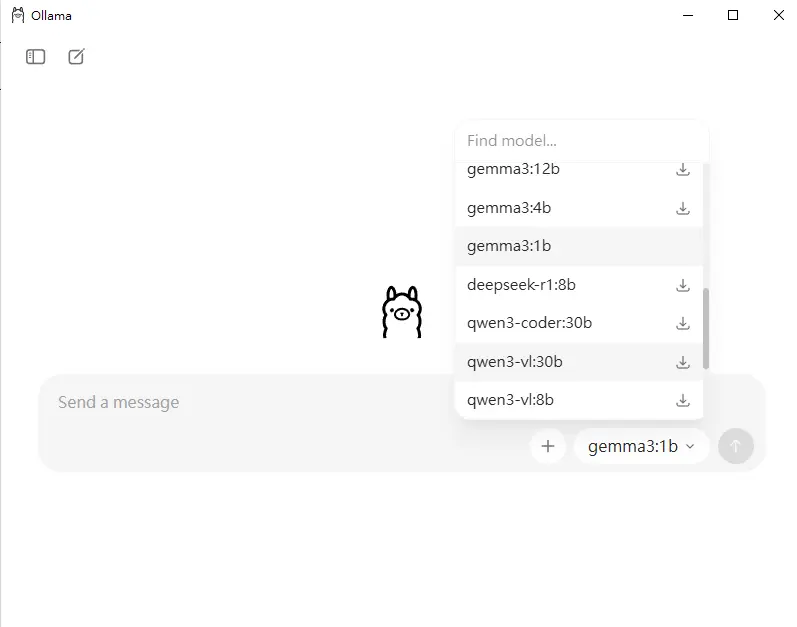
4.右下角可以選擇想使用的開元模型,這邊測試先選擇 Google 出品的 gemma3 1b模型,並提出第一個問題;程式他會自行下載對應的語言模型,連指令都可以不輸入了。
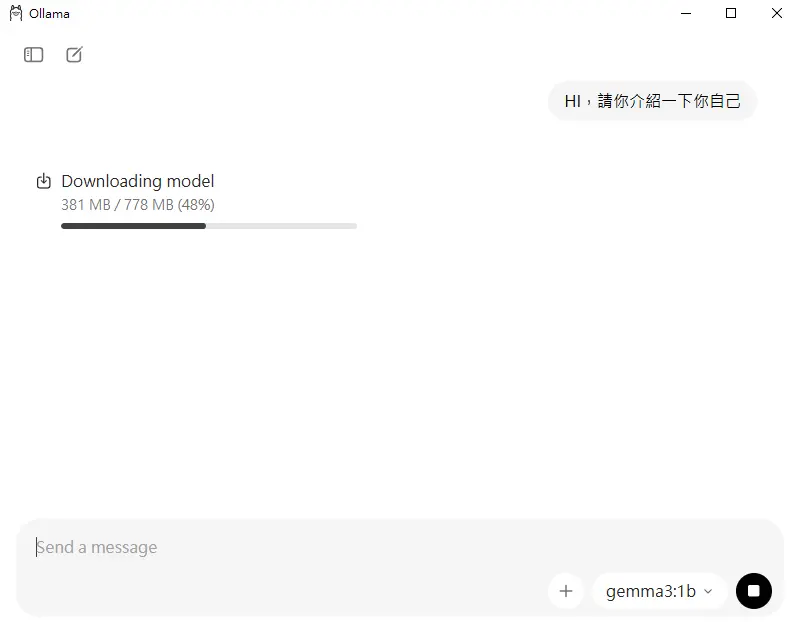
5.當對應的語言模型下載之後,程式會開始調用該模型並針對問題進行回答。
Linux 安裝
使用官方 Script:
curl -fsSL https://ollama.com/install.sh | sh
Code language: Bash (bash)Ollama 的基本指令與使用方式
如果你喜歡使用命令提示字元 或者是 終端機,也可以使用指令方式命令 Ollama 。
執行模型
ollama run {模型名稱}
Code language: Bash (bash)下載模型
ollama pull {模型名稱}
Code language: Bash (bash)列出已安裝的模型
ollama list
Code language: Bash (bash)停止運行
終端機按 Ctrl + C。
如何使用 Ollama 的 API
基本示例
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt": "什麼是 Ollama?"
}'
Code language: Bash (bash)回應類型
API 回傳的內容為逐行 streaming text,這有利於串接 UI 或即時對話框。
Ollama 常見模型與適用情境
Llama 3 / Llama 3.1
適合需要均衡、通用能力的使用者。
Llama 系列在各項能力都相當平均:語言理解、邏輯推理、寫作、程式碼生成、長文表現都很穩定。3.1 的推理深度更高,對技術問題、複雜說明、結構化回答的表現更成熟,是本地部署中最通用的主力模型之一。
Qwen 2 系列
中文能力強,非常適合華語使用者。
在中文語感、語法自然度、生活化對話、專業領域詞彙等方面都表現突出,能精準掌握中文脈絡與用詞。輸出風格自然流暢,中文寫作、摘要、筆記整理都特別強,是目前開源模型中中文能力最具優勢的系列。
Mistral 系列
速度快、效能佳,資源需求較低。
Mistral 的架構以高效率著稱,在同等參數量下推理速度快、記憶體占用低。雖屬輕量模型,但語言生成品質仍然不錯,尤其在多輪對話與中短篇輸出上表現穩定,非常適合需要高速度或頻繁互動的場景。
Phi 3
適用於 GPU 記憶體有限或輕量使用者。
Phi 3 是專門為小資硬體與行動設備優化的高效模型,以極少的參數量達到出乎意料的語言品質。風格清晰、邏輯乾淨、回答結構明確,非常適合快速啟動、高速測試或想節省運算資源的使用者。
Gemma
品質穩定,適合需要高一致性的生成內容。
Gemma 的語言風格整齊、邏輯性強、句型一致性高,輸出呈現相對正式且可靠。即使模型尺寸不大,也能維持良好的品質與安全性,是偏好穩定、乾淨輸出的使用者常用的開源模型。
使用 Ollama 所需的硬體需求
使用 GPU 進行推論的硬體建議
模型的參數越多,所需要的 VRAM (顯卡記憶體)就需要越高。
- 7B 模型:4GB~6GB VRAM
- 13B 模型:8GB~12GB VRAM
- 30B 模型:需要高階 GPU,例如 4090
- 無 GPU:仍可跑,但速度較慢
使用 CPU 與記憶體 進行推論的硬碟建議
使用模型量化後的 GGUF ,檔案需完整載入 RAM (記憶體),使用CPU推論時請先確保記憶體比模型還要大。
Ollama 適合哪些人使用?
個人使用者
想用 AI 協助工作、內容創作、學習或離線使用。
Ollama 能在自己的電腦上直接跑模型,不必依賴雲端服務,適合寫作、筆記整理、學習輔助、翻譯、程式教學等日常需求。即使沒有強大硬體,也能用量化模型順暢運作,是一般使用者最容易入門的本地 AI 工具。
開發者
需要可本地化、低延遲、低成本的 LLM 環境。
Ollama 提供簡潔的本地 API、模型管理、版本控制與快速切換模型能力,非常適合整合到網站、應用程式、插件、聊天機器人或後端流程中。因支援 GGUF 與多種模型,開發者能快速測試、部署與迭代。
中小企業與團隊
希望保護資料隱私、建置私有知識庫或內部工具。
在本地或內網環境中部署模型,不需將資料傳到第三方雲端,有效降低隱私風險。可用於客服自動化、內部文件問答、企業 SOP 整理、行政流程加速等用途,且硬體成本相對可控。
AI 愛好者與研究者
想比較不同模型、測試模型表現或製作工具。
Ollama 支援各種開源模型與多種量化格式,能快速切換、載入與調整模型,適合做 Benchmark、Prompt 測試、模型行為比較、插件開發、教育用途與個人研究實驗。
結論:
Ollama 讓大型語言模型變得容易使用,安裝簡單、模型多樣、運行迅速、具備本地 API、隱私完全可控。不論是想替代雲端服務、開發 AI 工具、打造自治環境,或完善你的工作流程,Ollama 都是一套非常成熟且值得使用的解決方案。


